

It's been a while since the last time I visited my favorite restaurants in New York. Hmm...I really miss them. I'm always wondering how many restaurants are there in New York, but I didn't find a good source. I did find a dataset that contains partial information about the restaurants in Baltimore in JSON (JavaScript Object Notation). Since Baltimore is one of my favorite cities and JSON is my favorite format, let's create a topic of using Python to manipulate JSON!
Not every dataset comes ready for analysis, the purpose of this blog is to give you an idea of how to deal with those missing information and use the analytical goal as a guide to manipulate the dataset.
Dataset:
Restaurant.json (This data set was updated in April, 2015 which may contain incomplete and incorrect information.)
At the first glance of the dataset, I found there's no zip code associate with the address, and the geographic information is not provided. If we want to visualize the restaurant in Baltimore and find the most popular place and opportunity for a new business, we need several steps to complete the information.
Let's discuss a new format - JSON.
What is JSON?
JavaScript Object Notation (JSON) is an open standard file format for sending data by HTTP request between browsers and other applications. I like to visualize the structure of a format to get a better idea of how to deal with it in the future. Here is an example:
{
"name": "Yuchen",
"location" : ["US", "Earth"],
"pet" : "Shiro",
"sibling": null,
"food" : [{"fruits":["cherry","banana","apple"]},
{"vegetables": ["Celery","cucumber"]},
{"meat" : ["beef","duck","pork"]}],
"mood" : ["happy","calm"]
}JSON is more like a combination of the data structures of Python, which makes it flexible and easy to extract information and transform to python objects.
🤪Check out my blog for the Python Data Structures Cheatsheet!
Let's go back to our dataset. This JSON file contains two parts - 'metadata' and 'actual data'. The metadata is configuring the fields and categories for abstraction. The file configures the field categories and lists available, as well as what type of values are permitted for each field. Read more about metadata here.

For the actual data which is a collection of restaurant info, I recommend to use a 'beautifier' to transform the original codes to a readable structure.

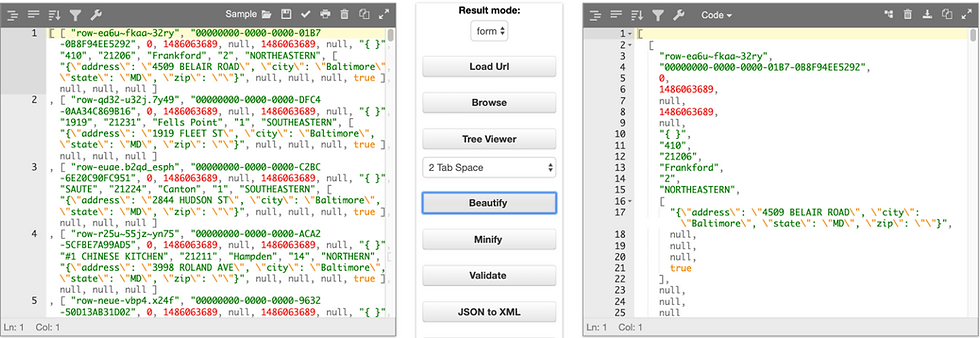
Now let‘s get into to the topic - how we use Python to extract information from JSON.
Step 1 - Make Some Necessary Imports and Check Your Current Working Directory
import json
import os
import pandas as pd
cwd = os.getcwd()
files = os.listdir(cwd)
cwdStep 2 - Load JSON
db = json.load(open('Desktop/test.json'))
len(db)*Step 3 - Give Yourself Some Example of How the Data Looks Like
If you are an expert, you can skip this step, but I like to give myself some examples before coding. Namely, I tried to slice the first row if the data to see the types and content first. In this example, I tried to get the complete address of a restaurant, so I applied the 13th element of the first chunk of data in the JSON file.
# Explore the data type
db_address = db[0][13][0]
print(db_address)
print (type(db_address))
# Transform string to dictionary
import ast
db_address_res = ast.literal_eval(db_address)
print(db_address_res)
print (type(db_address_res))
In the output, I noticed the type of 'db_address' is 'string', so I added one more step to transform the type to a dictionary by using 'ast.literal_eval' function. Now we have an idea of how the data look like and we've done dealing with the type.
Step 5 - Append All the Address in JSON to a Data Frame
In this step, we're using a loop to get the address in each data chunk in JSON and append the result to a new Dataframe. In this example, I used the first element (db[0], db[1], db[2]...) of each restaurant as the index.
rec = 0
db_address_res_1 = []
restaurant_address_df = pd.DataFrame()
for rec in range(len(db)):
db_address_res_1= ast.literal_eval(db[rec][13][0])
restaurant_address_df_1 = pd.DataFrame(db_address_res_1,index = [db[rec][0]])
restaurant_address_df = restaurant_address_df.append(restaurant_address_df_1)Step 6 - Combine the Columns 'address', 'city' and 'state' to a New Column 'completeAddress'
Here, I added a new column 'completeAddress' to store the address of the restaurant.
restaurant_address_df['completeAddress'] = restaurant_address_df[restaurant_address_df.columns[0:3]].apply(lambda x: ','.join(x.dropna().astype(str)),
axis=1
)
restaurant_address_df['completeAddress'][1]*Step 7 - Example of the Geo Location
You may skip this step, but I like to give myself an example of the output of a new function. In the output, we can find the detailed address with zip code and the geographic coordinates (latitude, longitude).
🤪Yuchen's tip: you can use your email address as 'user_agent' in the 'Nominatim' function.
from geopy.geocoders import Nominatim
locator = Nominatim(user_agent= 'your email address')
for i in range(16):
location = locator.geocode(restaurant_address_df['completeAddress'][i])
locationOut:
Location(Biddle Street, Maryland Manor, Rosedale, Baltimore County, Maryland, 21237, United States of America, (39.3097142, -76.5252203, 0.0))
Step 8 - Find the Geographical Information for all Restaurants
Given the example, we can apply the 'Nominatim' function to the entire DataFrame by a loop function. The reason that I used one more step to identify 'Na' is that I noticed not all the addresses can be found via GeoPy. I haven't figured out this problem, so I just filled them with 'Na' temporarily.
from geopy.geocoders import Nominatim
locator = Nominatim(user_agent= 'your email address')
temp_geo = pd.DataFrame()
geo_2 = pd.DataFrame()
for i in range(len(db)):
location = locator.geocode(restaurant_address_df['completeAddress'][i])
if not location:
Latitude = 'Na'
Longitude = 'Na'
data = {'Latitude':['Na'],'Langitute':['Na'] }
temp_geo = pd.DataFrame(data,index =[db[i][0]])
geo_2 = geo_2.append(temp_geo)
else:
Latitude = location.latitude
Longitude = location.longitude
data = {'Latitude':[Latitude],'Langitute':[Longitude] }
temp_geo = pd.DataFrame(data,index =[db[i][0]])
geo_2 = geo_2.append(temp_geo)Step 9 - See the Final Result
new_restaurant_df = restaurant_address_df.join(geo_2)
new_restaurant_df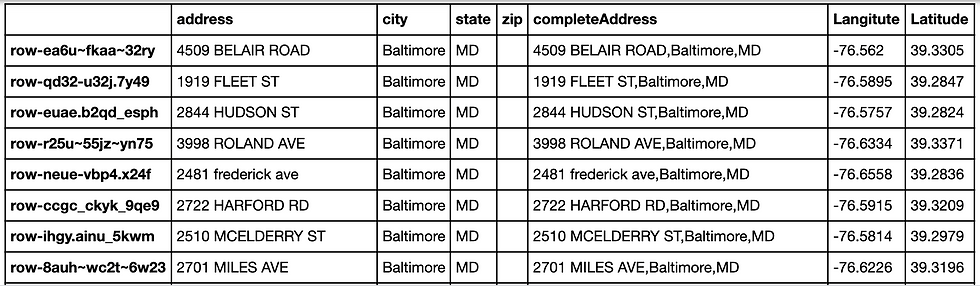
This is not the end of exploration, our goal is to utilize the prepared data to find insights. In this case, we may visualize the locations of the restaurants on a map to see the distribution, which can be done via Python or Tableau. The business case can be looking for the best locations to open new restaurants. We can also investigate why some restaurants cannot be found via GeoPy. There's much more to do with the data. I'll keep updating this blog to show more valuable insights.
View the codes at my GitHub Repository.
😊 Happy analyzing!
Comments